Data science teams build analytics pipelines, machine learning models, and data products where experimental iterations, model validation, and production deployment require careful coordination.
Your team explores datasets, trains models, and deploys prediction services while business stakeholders expect immediate insights. Notebook experiments need reproducibility tracking, model performance degrades over time, and data pipeline failures affect downstream reports.
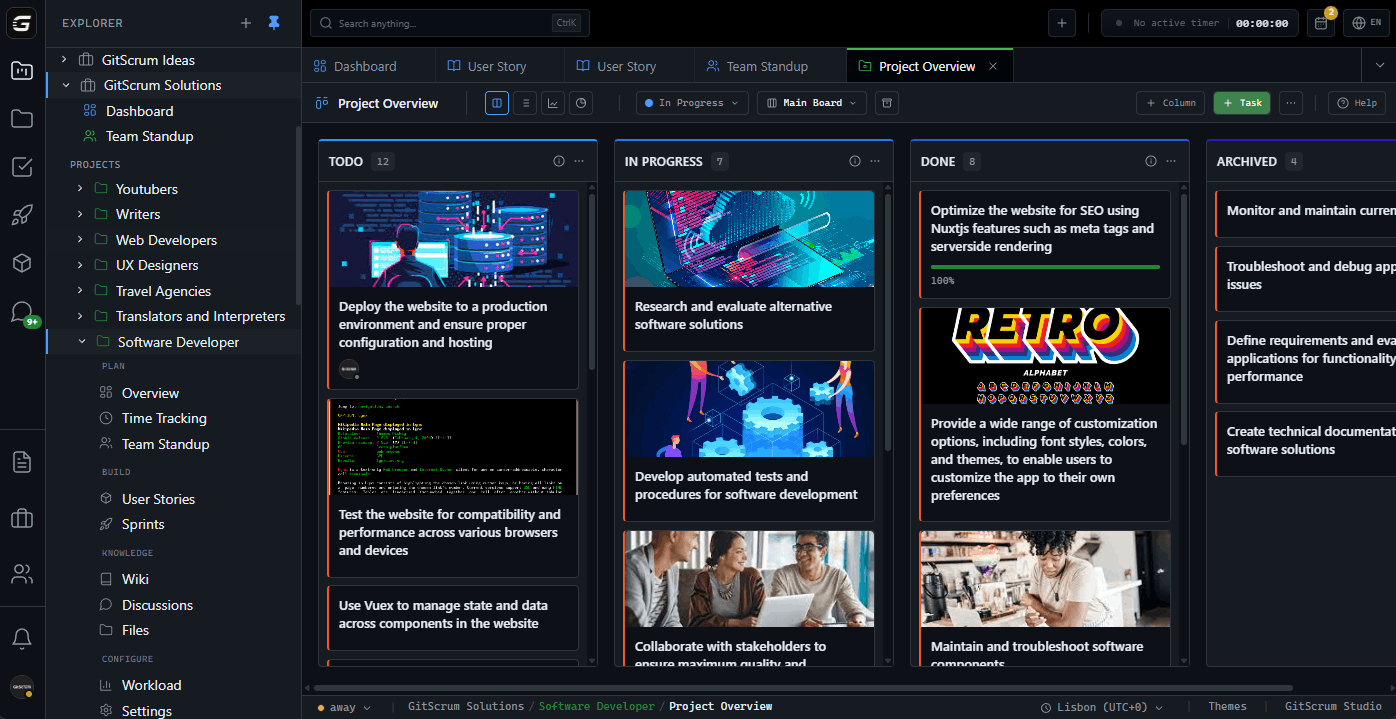
Sprint planning balances exploration with production work, Wiki documents data dictionaries and model specifications, and Git integrations track code versions against model experiments. Discussions coordinate with business stakeholders on requirements.
GitScrum helps data teams: boards separate exploration from production, user stories capture business questions with success metrics, and time tracking distinguishes research from implementation.
The GitScrum Advantage
One unified platform to eliminate context switching and recover productive hours.







